KittenTTS(轻量级文本转语音模型)简介
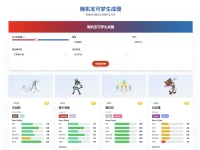
KittenTTS是一个开源的轻量级文本转语音模型,最大的特点就是其轻量级和高性能。该模型的大小不到 25MB,拥有 1500 万个参数,可以在那些没有 GPU 的设备上运行,极大地方便了开发者的应用,非常适合适合希望在轻量级环境中实现高质量语音合成的开发者。

主要特点
- 超轻量级:KittenTTS 的模型体积小,适合在资源有限的环境中使用,确保了快速的部署和高效的运行。
- CPU 优化:该模型经过优化,能够在没有 GPU 的设备上流畅运行,适合各种计算环境。
- 高质量语音:KittenTTS 提供多个高质量语音选项,用户可以根据需求选择合适的声音,例如男声和女声等。
- 快速推理:该模型针对实时语音合成进行了优化,确保生成的音频质量高且延迟低。
KittenTTS(轻量级文本转语音模型)官网及教程
安装起来也非常简单,只需使用 pip 命令即可:
pip install https://github.com/KittenML/KittenTTS/releases/download/0.1/kittentts-0.1.0-py3-none-any.whl使用示例:
from kittentts import KittenTTS
m = KittenTTS("KittenML/kitten-tts-nano-0.1")
audio = m.generate("这个高质量的 TTS 模型无需 GPU 工作", voice='expr-voice-2-f')
import soundfile as sf
sf.write('output.wav', audio, 24000)