很多人不知道linux怎么安装hadoop,hadoop作为一个能够对大量数据进行分布式处理的软件框架用户可以在不了解分布式底层细节的情况下,开发分布式程序,很多新手不知道如何在linux环境中安装hadoop,今天就为大家带来这个linux安装hadoop的详细步骤,希望能够帮助到有需要的网友。
linux安装hadoop
演示环境:
- Linux系统:centos 7.4
- JDL:jdk 1.8
- Hadoop:Hadoop2.7.7
- 虚拟机:VMware Workstation 12 pro
- 本机系统: Windows 10
- Master主机:192.2168.1.180
- S1主机:192.168.1.181
- S2主机:192.168.1.182
一、安装前准备工作:
1.更新YUM源
#yum -y update
2.关闭防火墙
#systemctl disable firewalld
3.关闭安全内核
#vim /etc/selinux/config
SELINUX=disabled
4.修改主机名
#hostnamectl set-hostname master
vim /etc/hosts
192.168.1.180 master
192.168.1.181 s1
192.168.1.182 s2
5.安装时间同步器,本次同步上海时区的时间
下载时间同步模块yum -y install ntpdate
连接远程服务器 ntpdate -u time1.aliyun.com
修改文件 ntpdate -u ntp.api.bz
查看系统时间 hwclock –show
查看硬件时间 hwclock -w
永久保存 date
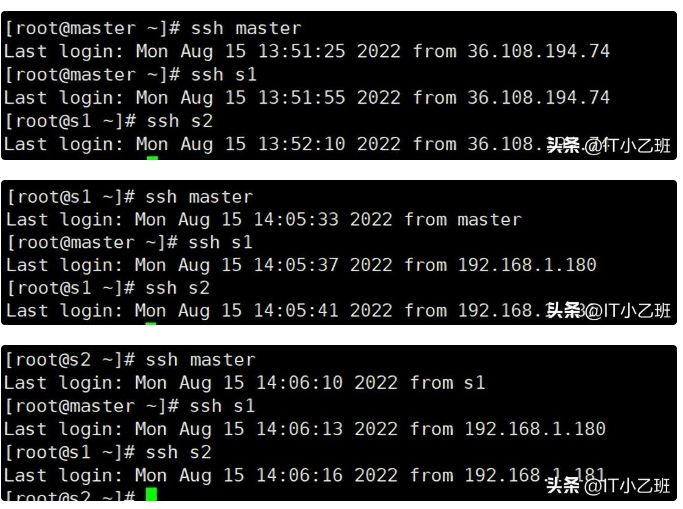
6.制作免密码登陆,分别在3台主机中执行
输入ssh-keygen -t rsa,然后确认回车
在master主机中输入:
ssh-copy-id master ssh-copy-id s1 ssh-copy-id s2
在s1主机中输入
ssh-copy-id master ssh-copy-id s2
在s2主机中输入
ssh-copy-id master ssh-copy-id s1
测试ssh登录
二、安装JDK 1.8
1.官网下载
jdk-8u101-linux-x64.tar.gz
2.上传到服务器tools目录及解压
#mkdir /usr/local/java 创建路径
#tar -zxvf jdk-8u101-linux-x64.tar.gz -C /usr/local/java
3.修改环境变量(重要,仔细仔细仔细)
#vim /etc/profile
添加如下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_101
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#source /etc/profile 立刻刷新

4.图上图所示,测试验证;
三、安装Hadoop及配置文件修改
1.官网下载
2.上传解压
#tar zxvf hadoop-2.7.7.tar.gz -C /usr/local
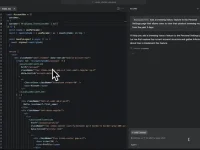
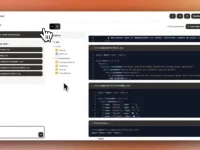
3.配置文件修改(
/usr/local/hadoop-2.7.7/etc/hadoop)

如上图所示,修改hadoop-env.sh
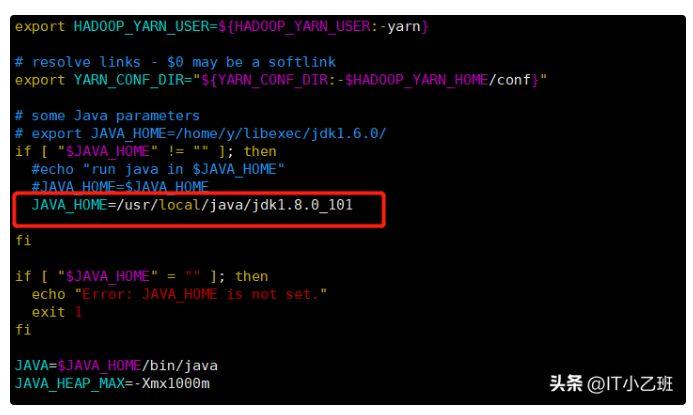
如上图所示,修改yarn-env.sh
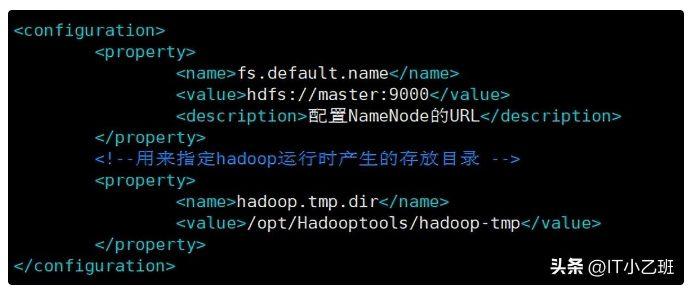
如上图所示,修改core-site.xml
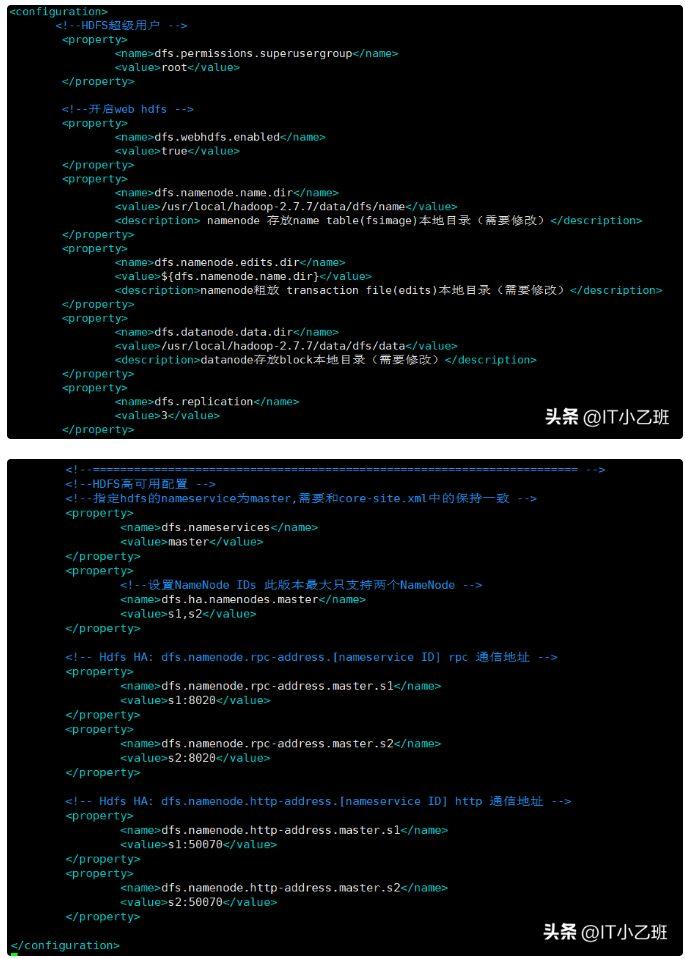
如上图所示,配置文件系统hdfs-site.xml

如上图所示,配置计算框架mapred-site.xml

如上图所示,配置文件系统yarn-site.xml

如上图所示,修改slave
将master上hadoop目录分发到s1/s2上,将 master 上的 hadoop-2.7.7文件夹复制到s1,s2上。
依次运行以下命令:
scp -r /usr/local/hadoop-2.7.7 root@s1:/usr/local/
scp -r /usr/local/hadoop-2.7.7 root@s2:/usr/local/
检查s1/s2是否拷贝过去
4.配置环境变量
vim /root/.bash_profile
PATH=$PATH:$HOME/bin
export JAVA_HOME=/usr/local/java/jdk1.8.0_101
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:
然后执行命令 source /root/.bash_profile 使配置生效
重复上述操作将s1,s2虚拟机的环境变量也配置成这样。
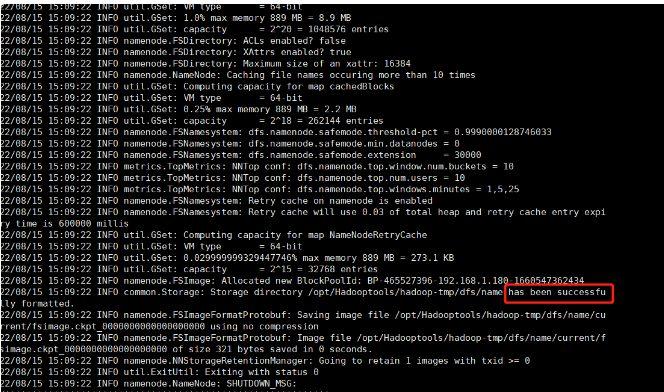
5.格式化系统
该命令只能在master上执行,且只能执行一次,不可多次执行。
hdfs namenode -format
四、启动Hadoop集群
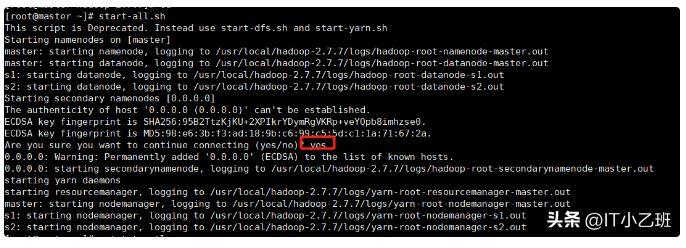
1.在master上启动
#start-all.sh
根据提示信息,输入yes
2.测试访问,查看端口启动情况
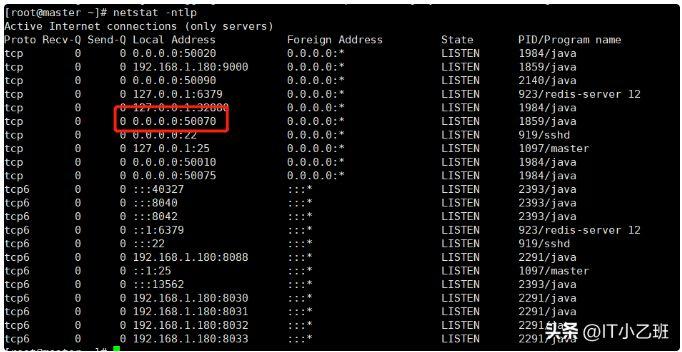
打开192.168.1.180:50070
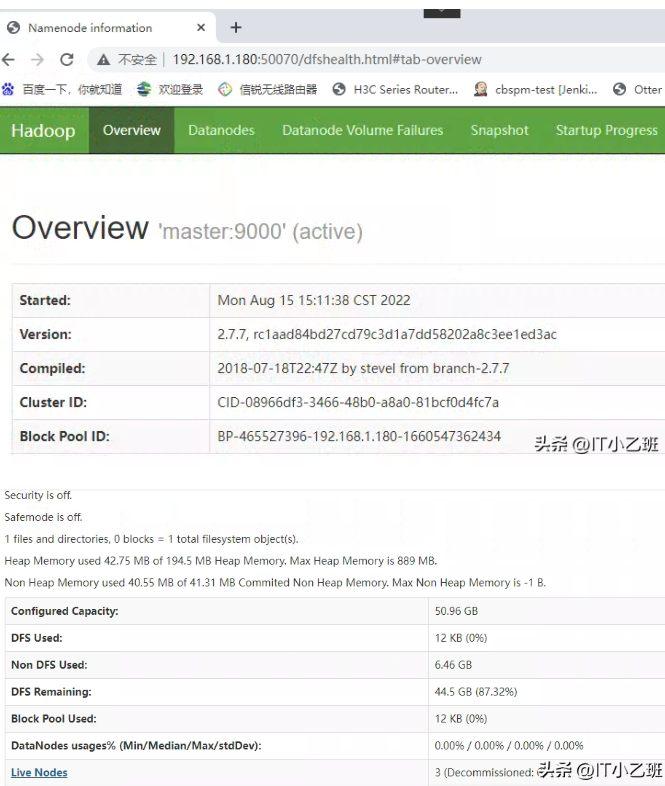
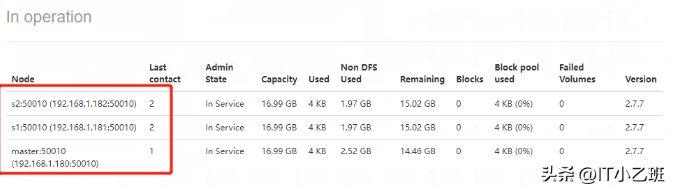
备注:点开livenodes查看现在是否有3台节点同时在线,如果不是3台,则说明配置有问题,需要重新排错,按照教程前面内容仔细检查,如果显示是3台主机在线,则表明配置成功。
3.执行jps命令查看master/s1/s2进程。